
3 steps towards a faster TRU (Time to Reviewable URL)
TRU (Time to Reviewable URL) is the amount of time it takes for a code change to be reflected onto a public URL.
Note: Not producing reviewable URLs yet? Don't worry, there's still some valuable information in this post that will help lead you there.
How to measure TRU?
Your TRU score is measured in minutes/seconds. It's a timer that is triggered by a code change such as a pull request, and it ends when that change can be reviewed by others.
Example: if your CI process follows the common pattern of performing some static analysis, then building your app, followed by tests, it's not uncommon to see a timeline like this:
Note: These numbers are very conservative, I've seen much higher ones in real applications, but we'll use this rounded down '10 minutes in CI' as a way to frame our improvements.
The green block at the end of the pipeline is where a public URL is made available to others, therefore, in this setup: TRU = 10+ min.
Converting that fact (of deploying to a public URL in 10+ min) into a measurable metric (TRU) helps start a conversation about how to improve it.
So, what's a good TRU?
The 10+ min example above is not a good TRU. It might be acceptable as a first step - for example if you're only just embarking on the concept of Preview URLs, but in reality we all know of CI processes that far exceed 10+ min.
We need to aim higher, for a TRU of less than 1 minute
Getting to this point would be a game-changing improvement to your organization. Going from opened PR to a public URL in less than 1 minute, creates entirely different workflows.
The following advice in this post is admittedly easier to enact on greenfield projects, where you have more freedom to choose your tools and processes. But, even on those projects where you think a one minute build is absurdly unrealistic, you can still work to reduce your TRU using the tips and tricks I mention along the way.
Why is a faster TRU better though?
Faster delivery, lower costs, easier maintenance and a better user experience.
Optimising for a faster TRU, especially in a team environment, creates a culture that values deliverable software, deeper collaboration (through transparency) and better engineering practices overall.
- If your TRU is trending downwards (eg: towards faster deploys) you are quite literally speeding up every aspect of your software delivery pipeline. Getting eyes on your work sooner than you could before, means you not only have the opportunity to catch bugs and regressions sooner, but you can also solicit reviews from peers earlier in the project's lifecycle too. This will ultimately lead to better quality software, delivered in less time.
- Having a low TRU is also a strong indicator that you've fought for low-complexity - both in your application code but also in your delivery processes as a whole. Low-complexity codebases and processes are easier to maintain and adapt in the long term.
- If you have a low TRU, it probably means your CI bills are lower too since it'll be doing less work for each change.
The inverse of those benefits tells a bleaker, but more accurate picture based on what I've seen in Frontend-heavy applications.
- If your TRU is trending upwards (eg: towards longer deploys) it normally means your team is becoming slower at delivering changes overall. If it's taking longer to deploy a preview URL than it did before, then the changes that caused that slowdown are directly impacting the speed in which reviews can occur. That, in turn, will cause projects to take longer to complete than they did in the past.
- If the main culprit of a high TRU is the build time, that tends to point to a project that has a high dependency count along with many 'layers' that make up the application, and its associated tools. Your build/CI pipeline is doing a lot of heavy work in this scenario, which is a symptom of not prioritizing simple tools and processes.
- Projects in this state tend to be more challenging to maintain, adapt and upgrade due to the interwoven dependency graphs, adding further delays.
Who benefits from a faster TRU?
Managers will appreciate a faster TRU—having changes ready to review more quickly will obviously speed up projects. You can fit more iterations and deployments into a day, and so your work will progress more quickly.
Collaboration with Designers, UX and Accessibility folk will be more productive too. If someone can review a change 40 seconds after you made it, your combined efforts will pay off sooner.
Meanwhile for the engineers, they will feel liberated and more confident to make changes at a faster pace. They will enjoy the burden of a long delivery pipeline being lifted, and can instead focus on making your product better for users.
Speaking of which, the most important beneficiary of all will be: your users.
Spending engineering time on reducing your TRU will naturally lead to lighter, more nimble software. If you actively work to lower your build and deployment times, you'll find that it rules out a whole category of processes, tool and dependencies automatically. Namely, the slow and bloated ones.
Lighter, faster software is accessible to a broader audience than the heavier, slower kind. It'll run better, for longer too, on devices of all kinds.
Ok, how do we get there?
We need a faster build process, with a more controlled environment and a prioritized preview deployment. Those are the 3 steps I am highlighting in this post.
Tough decisions will need to be made, and some real engineering will need to occur.
So let's go through the steps in order of difficulty:
Step 1: A fast build process
Everything hinges on this first step—without it, steps 2 and 3 won't have the same compounding effect.
Projects that never make it to a fast TRU are most often hamstrung by how long their bundlers run for in CI, so we need to aim for a build process that takes just a second or two.
Tools like esbuild can do an awful lot in a second or two, and they don't tend to lead you down the path
I've seen so often—where a well-meant setup can start to crawl in the build times.
A none-exhaustive list of rules you can apply, regardless of which specific tool you choose:
- Choose a modern, fast bundler - one that doesn't require a complex dependency graph of loaders/processors.
- Separate the bundling and building from all linting and formatting
- Favor micro libraries and frameworks that are closer to the web platform (lit, svelte, preact etc.)
- For styling, opt for any process that results in regular CSS files and CSS classnames - loaded with <link /> tags
- Use a preview "build target" as an opportunity to avoid expensive processing (more on this in Step 2)
If you have the luxury of choosing tools and processes on a new application, figure out how far you can
get with just esbuild (or similar).
Ensure you are separating the generation of production assets from any type-checking, linting or formatting. Sure, have ESLint/TypeScript running in parallel if you'd like, but the 'build' should not be not much more than crawling through your entry points and producing JS files on the other side.
Next, limit your dependencies massively, and audit them continuously. For React devs - try building on a basic setup of just Preact, Preact Signals + CSS modules. You might just be amazed how far you can get.
- Note: If you go down this route - I'd recommend against an alias of
preact/compat->React. I'd justimport preactdirectly. Pretending to be React gives the illusion that React-specific packages will 'just work.' I've found issues with this approach, and by just using Preact directly I've seen fewer bugs and fewer temptations to bring in packages that affect build times.- Sub-Note: Not choosing React (or aliasing with
preact/compat) also has the nice side-effect of encouraging you to seek out libraries that are framework-agnostic by default. Those tend to be lighter and more focussed on the web-platform as a default.
- Sub-Note: Not choosing React (or aliasing with
For styling, avoid any CSS-in-JS solutions. There's too much work needed to process them and tools like esbuild can
handle raw CSS + CSS module imports anyway. Let these tools produce a regular old CSS file, and you can load
it into your HTML just how the browsers prefer it.
import styles from "./app.module.css";
function App() {
// this is fine...
return <div class={styles.root}>...</div>
}
<!-- because you'll still end up with this, in your HTML (not JS) -->
<link href="styles.css" rel="stylesheet" />
For those outside the React world, or for those looking to avoid JSX too, take a close look at Svelte or Lit.
Whichever you choose, if the build time is going to be longer than a few seconds, then it's not really compatible
with a low TRU and should be avoided.
Now, regardless of which framework/bundler you choose, always consider what can be excluded from your build process.
For example, is it really necessary for all your assets to go through a bundler's pipeline? Is there anything you can
pre-process with other tools and just place in the public
folder like the old days?
What about that long, slow translation process—can that be done separately? Perhaps in the preview build (detailed next) you could configure the application to load a translation file at runtime over fetch (from the public folder)?. That would avoid executing a really complex build-time flow in the bundler (that often ends up including all locales—I've made that mistake before!)
These are just ideas—all of which in isolation might not make much difference. But, as a whole, employing this style of engineering discipline will lead you down the path to success.
If you've managed to convince your team that this is a worthwhile pursuit, you're already most of the way there, and you're standing out from the crowd. If your bundler process is just a second or two, you're never going to feel burdened by it.
The next step, is to create a more Controlled Environment.
Step 2: Controlled Environment
A Controlled Environment is a way of running your application with pre-defined, deterministic states.
It could include things like mocked data. That helps to avoid UX and Design work from needing slow services that are complicated to setup (like API backends) in the preview environment. It might even have some logic baked in to present the application in a known state for testing. No matter which level you reach though, the key word here is determinism.
When everyone visiting a specially configured URL is experiencing the same thing, reviews and sign-off will be faster.
Browser-based tests can use the configured URLs too—making them faster and less flaky. It's reasonable to assume you can reduce the length of your in-browser tests by 10x if you employ stricter rules around a controlled environment.
Having application states triggered by shareable URLs, as an example of a Controlled Environment, will enable more accurate collaboration. Then re-using those URLs in automated tests gives a greater confidence that the CI process will go green eventually. (This overlap between the Preview URL and your tests becomes crucial in Step 3, where we'll be seeking human reviews long before the automated tests have finished).
As always, the following examples are just things I've seen work well - so don't get too hung up on the exact tools or techniques—instead remain focussed on the goal of controlling your environment.
Creating a Controlled Environment with Build Targets
In other programming environments, the use of a 'build target' is a familiar concept. From a single codebase, often multiple build artifacts will be produced—each tailored to the environment in which they'll run. This is often (but not always) achieved with source-code annotations, like an attribute above a function, or some kind of special syntax.
You can use this kind of technique to produce a special preview build of your application that is pre-loaded
with knowledge of how to reproduce certain states. Controlling the external boundaries of your application is a
good practice anyway - and this technique just leans into it.
To make this work, we'll need basic bundler support and a single abstraction around whatever service you want to control.
Bundler support
Since I mentioned esbuild already, I'll keep the examples specific to it. Other bundlers will have different ways of
achieving the same output.
So, for brevity, let's just assume your application talks to it's backend over fetch. To load a different implementation
in the preview build, we can use a label like $PREVIEW: <expr>, and then configure esbuild to strip it out of the
production builds.
import mockFetcher from "./mocks.js";
// the default
const fetcher = globalThis.fetch;
// using a JavaScript label as something that the
// build can choose to leave in, or strip out.
$PREVIEW: fetcher = mockFetcher
Now we can configure esbuild to drop those $PREVIEW labels by default - this will act as the "production environment".
// the default, for the production builds
esbuild.buildSync({
...opts,
dropLabels: ['$PREVIEW']
})
Then, to create the preview build we just omit the $PREVIEW label.
// when --target=preview
esbuild.buildSync({
...opts,
dropLabels: []
})
On its own, this doesn't seem too useful, but in the case of this esbuild-specific idea, it will also strip the
import statement of ./mocks.js when unused (in the production build), meaning you have a safe entry point in
JS, where you can go further than plain mocks.
You can now add logic, timers, JSON files and most importantly, altering the preview behavior based on URL Search Params.
Making use of the URL
Now that we have an idea of what it means to create a 'preview' build - we can start to get creative about how we respond to requests and how other side-effecting services affect our application.
Let's look at a practical example, where a state-based bug has been occurring if a particular API request is delayed.
In this workflow, we'd always start from the URL - thinking about how this particular bug can be reproduced if given a
set of parameters are present. Let's say we decide to add ?mock.api.delay=1000. Then, inside the mock
implementation in ./mocks.js we can detect it easily and adjust how we'd respond.
// in mocks.js, not present in the production build
const url = new URL(location.href);
const delayOverride = url.searchParams.get('mock.api.delay');
// now use 'delayOverride' if it's not null to fake a slower response
Note: Mock Service Worker could be a good option here too, of course.
The implementation is left up to the reader, but the bigger picture here is that mock responses alone are sometimes not enough, and we'll often want to add some logic too.
Once you get into the habit of making more and more states representable with sharable URL params like this, you'll notice that people start sharing multiple review links when making changes, each tailored to highlight a particular state.
Those I've helped to understand and adopt these practices are full of praise for the boost in productivity.
It turns out that this is an excellent way to run UI tests too.
I've seen testing setups of all shapes and sizes. From hour-long E2E test suites that nobody dares to touch, to an over-reliance on unit-tests (and the fake confidence they bring) all the way through to fine-grained component testing where everything works in isolation (but not together). My take, after all these years, is to favor in-application testing, but with a strict rule around controlling the environment.
With the correct level of control in place, it's a joy to work with tools like Playwright - with tests that are somewhere between E2E and integration. If each test fully loads the application, but it's configured to load the preview build, then we can use the same URL search params that reviewers are using in the public URLs. However, now we're using them as test cases.
This creates a really nice development cycle where your tests are fast, predictable and end up being a library of URLs to reference later.
Note: I'm deliberately omitting information about how any data/service mocking is implemented. There are lots of ways to achieve it, each with their own benefits/tradeoffs. Instead I just want to emphasise the idea of sharing URLs with previews and tests.
Make the preview URLs load the preview build
Now the easy part. Once you've figured out your bundler's preferred way to create a specialized 'preview' build like the prior example,
you just need to ensure that your CI process knows when to use it. When deploying to the preview URLs, always build the
"preview" target. Otherwise, build as normal.
If you've gotten to this point in the advice, you might already have a 1 second bundler process, along with a
special preview build target all working nicely together. If you do, you're well on the way to a seriously productive
project with excellent collaboration.
You'll just want to ensure nothing else in CI is slowing down these preview URLs from deploying...
3: Prioritizing the preview deployment in CI
An often overlooked optimization—don't let other checks/processes delay your preview URLs!
There's no bigger fan of static-analysis and tests than yours truly - both I consider to be mandatory for any team of engineers. But after so many years of participating in this industry, I've come to realize you can have your cake, and eat it too.
You can have discussions with Product Managers and Designers about a Preview URL that was created in seconds, all whilst the 'rest' of the CI checks are occurring in the background.
In the end, you're not going to ship to production without those green check marks anyway, so you might as well get ahead of the game and use that time to have people looking at your work.
Remember, if you've followed the advice from Step 2 - most of your browser-based tests should be running against the preview build too, so you can be confident that reviewers and automated tests are evaluating the same work!
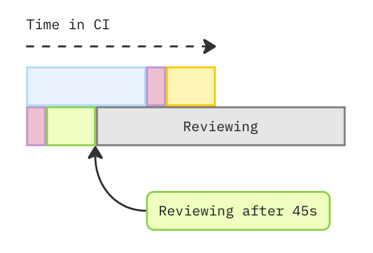
Run a build + Deploy as early as possible
In the 10+ minute example, we saw how the preview URL was only deployed when everything prior completed successfully.
Now, Step 3 of my advice is to free your engineers from the slow-down caused by those other processes, and let a deployment to a preview URL happen as soon as humanly possible.
Because of Step 1 (a faster build process), you don't need to worry about running the build more than once. So, for the sake of getting a really fast TRU and getting eyeballs on your work as soon as possible—why not ensure your processes can handle a concurrent flow that only includes a build + deployment?
Even if your build is 10 seconds, and then your preview deployment is 35 seconds, that means a TRU of 45 seconds is an achievable goal!
Summary
TRU (Time to Reviewable URL) is a metric that you can start tracking immediately. It's a proxy metric that can help to expose the overall health of your software and its delivery pipeline. A team that maintains a fast TRU and continuously looks to improve it, is likely delivering better work, more quickly, than those that do neither.
The 3 Steps I've presented above will get you closer to a fast TRU. It takes tough decisions and solid engineering work, but the rewards are worth it.
The metric can be used to inform engineering decisions. For example, by referring to it when new tools and processes are being proposed. Ask: 'How will this impact our Time to Reviewable URLs?'.
Managers and Tech Leads: Ask your Engineers if there's any low-hanging fruit that can be picked off in the name of reducing your teams' TRU.
Engineers: On greenfield projects, deeply consider which tools, libraries and processes have the highest likelihood of maintaining a low TRU in the long term. Choose lean, choose light.
On brownfield projects: gather your baseline metrics (how long it's taking to deploy right now) and start to paint a picture of where the biggest delays are. Then in downtime, or during a maintenance window, you can work towards lowering your TRU to the benefit of all involved.